pyside6-deploy
This tool is intended to help in-experienced developers with freezing and compiling tools to get an executable from their PySide project. We include a simple wrapper for Nuitka, so you can just run pyside6-deploy your_file.py to get it done.
此工具旨在帮助经验丰富的开发人员使用冻结和编译工具,从PySide项目中获取可执行文件。我们为Nuitka提供了一个简单的包装器,因此您只需运行pyside6-deploy your_file.py来完成它。
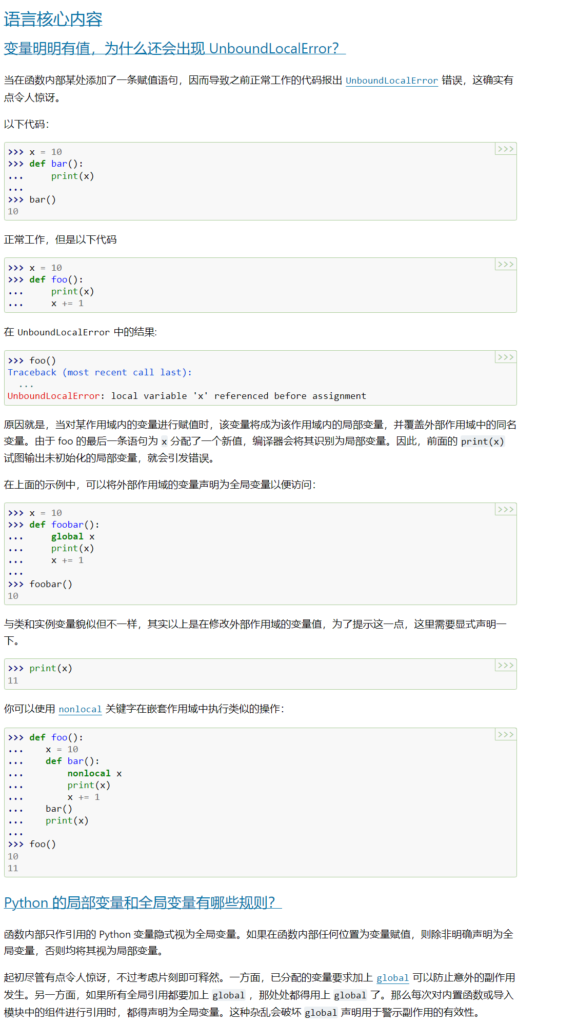
类属性和实例属性
class test:
a = 1;
def __init__(self):
print(self.a)
self.a = 2
print(self.a)
print(test.a)
test.a = 2
print(test.a)
new = test()
print(new.a)输出结果:
1
2
1
2程序员注意事项: 在类定义内定义的变量是类属性;它们将被类实例所共享。 实例属性可通过 self.name = value 在方法中设定。 类和实例属性均可通过 “self.name” 表示法来访问,当通过此方式访问时实例属性会隐藏同名的类属性。 类属性可被用作实例属性的默认值,但在此场景下使用可变值可能导致未预期的结果。 可以使用 描述器 来创建具有不同实现细节的实例变量。来源
全局解释器锁(GIL)
全局解释器锁(GIL)是 Python 解释器的一个重要组成部分,它是一个互斥锁,用于控制在任何时刻只有一个线程可以执行 Python 解释器中的字节码。这个锁可以确保在多线程环境下,Python 程序能够正确地执行,避免了并发访问共享数据时的竞态条件和数据不一致性问题。
GIL 的作用是在解释器级别上限制了线程的并发性,因为在任何时刻只能有一个线程持有 GIL,获得 GIL 的线程可以执行 Python 字节码,而其他线程则被挂起。这样做可以避免多个线程同时访问共享数据时的竞态条件和数据不一致性问题,因为只有一个线程可以访问共享数据,而其他线程必须等待。
GIL 的存在在某种程度上限制了 Python 的多线程并发性能,因为在任何时刻只有一个线程可以执行 Python 代码,而其他线程被挂起。如果程序中的多线程任务是 CPU 密集型的,那么这个限制可能会对程序性能产生重大影响。然而,在 I/O 密集型任务中,由于 I/O 操作通常会导致线程挂起,因此 GIL 的限制通常不会成为程序性能的瓶颈。
需要注意的是,GIL 是特定于 CPython 解释器的实现细节,其他 Python 实现(如 Jython、IronPython 和 PyPy)可能没有 GIL 或使用不同的锁实现。同时,对于需要高度并发性的应用程序,可以使用其他并发编程技术(如多进程、协程等)来避免 GIL 限制。
Python 的协程
协程(用户态线程)
由于线程分用户线程和内核线程。内核线程再调用的时候可以去不同的核心去操作。所以多线程是可以利用到多核的。
Python 的协程(coroutine)是一种轻量级的并发编程技术,可以在单个线程中实现并发执行多个任务的效果,从而提高程序的性能和响应能力。下面是一个简单的协程示例:
import asyncio
async def greet(name):
print(f"Hello, {name}!")
await asyncio.sleep(1)
print(f"Goodbye, {name}!")
async def main():
await asyncio.gather(
greet("Alice"),
greet("Bob"),
greet("Charlie")
)
asyncio.run(main())在这个例子中,greet 函数是一个协程,它使用 async def 声明,这表示它是一个异步函数。该函数包含了两个打印语句和一个 await asyncio.sleep(1) 语句。await 表示当前的协程需要等待一个异步操作完成,而这里的异步操作是 asyncio.sleep(1),它会让协程挂起一秒钟,然后恢复执行。
在 main 函数中,使用 asyncio.gather 函数来并发执行三个 greet 协程。这个函数会等待所有协程执行完毕,然后返回它们的结果。
运行这个示例后,我们会看到类似如下的输出:
Hello, Bob!nHello, Charlie!nGoodbye, Alice!nGoodbye, Bob!nGoodbye, Charlie!可以看到,在这个示例中,三个 greet 协程被并发执行,每个协程执行到 await asyncio.sleep(1) 时会挂起,然后切换到其他协程继续执行。这样可以实现在单个线程中同时执行多个任务的效果,从而提高程序的性能和响应能力。
需要注意的是,在使用协程时需要注意避免阻塞操作,因为协程是在单个线程中并发执行的,如果一个协程阻塞了,那么其他协程也会被阻塞。通常可以使用异步 I/O 或者线程池等技术来避免阻塞操作,从而提高程序的性能和并发能力。
Python协程(coroutine)是一种更高级的控制流结构,可以看作是生成器的扩展。与生成器类似,协程也是通过关键字 yield 来暂停和恢复执行的,但协程可以在暂停的地方重新启动执行,甚至可以从外部发送数据进入协程。要理解Python协程的底层原理,以下几个关键点是必须掌握的:
- 生成器:
- 生成器是迭代器的一种特殊形式,通过
yield关键字生成值。 - 调用
yield的时候,生成器会暂停执行,并将值返回给调用方。 - 当生成器函数再次被调用时,会从上次
yield的位置继续执行。
- 生成器是迭代器的一种特殊形式,通过
- 生成器对象:
- 当一个生成器函数被调用时,它返回一个生成器对象,而不是立即开始执行函数体。
- 生成器对象实现了迭代器协议 (
__iter__和__next__方法)。
- 协程基础:
- 协程也是通过
yield实现的,但更进一步的是,协程允许通过yield向其内部发送值。 - 协程通过
yield表达式接收外部发送的数据,这使得协程不仅能生成值,还能接收值并控制执行流程。
- 协程也是通过
yield表达式:yield可以作为表达式来使用,例如value = (yield some_value),这样yield不仅返回some_value,而且可以通过send方法接收外部传入的value。
- 协程的状态控制:
- 协程的状态由其生成器对象的生命周期管理。当调用
next()或send()方法时,协程会从上次暂停的地方继续执行。 - 当协程运行结束时,会引发
StopIteration异常。
- 协程的状态由其生成器对象的生命周期管理。当调用
async和await:async def声明一个协程函数,await关键字用于暂停协程的执行,等待一个耗时操作完成。- 底层仍然是基于生成器的工作机制,但有更好的语法支持和语义约束。
下面是一个简单的例子来演示协程的工作机制:
python
复制代码
def simple_coroutine(): print('Coroutine started') x = yield print('Received:', x) # 创建生成器对象 coro = simple_coroutine() # 启动协程 next(coro) # 输出: Coroutine started # 向协程发送数据 coro.send(42) # 输出: Received: 42
在这个例子中,simple_coroutine 是一个简单的协程,使用 yield 来暂停和恢复执行。在 coro.send(42) 调用之后,值 42 被发送到协程内部,并赋值给变量 x。
底层实现原理
Python的协程底层实现主要依赖于生成器的状态管理机制。每次调用 yield 时,生成器对象的状态会保存到生成器帧中。生成器帧包含当前执行的位置(指令计数器)、局部变量和堆栈状态。通过调用 next() 或 send() 方法,生成器帧会被恢复,并继续执行直到遇到下一个 yield 或函数返回。
在Cpython中,协程的执行由_PyGen_Send函数控制,该函数负责恢复生成器帧的执行,并处理yield表达式的值传递。协程的高级特性如async和await则通过事件循环(如asyncio)进行管理,提供异步I/O操作的支持。
总结起来,Python协程的底层原理主要基于生成器的状态管理机制,通过yield实现暂停和恢复执行,并通过事件循环实现异步操作。这使得协程在处理异步编程任务时非常高效和灵活。
生成器
Python的生成器是一种特殊的迭代器,可以用来生成一系列的值,而不需要一次性将所有值存储在内存中。生成器可以通过 yield 关键字来定义,在函数执行时,当遇到 yield 语句时,会将当前函数的状态保存下来,并返回一个生成器对象。每次从生成器中调用 __next__() 方法时,函数会从上次暂停的地方继续执行,直到遇到下一个 yield 语句或函数结束。
生成器的好处在于,它可以节省内存空间,并且在处理大量数据时,可以实现按需生成数据,提高程序的效率。下面是一个简单的示例代码,演示了如何使用生成器来生成斐波那契数列:
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
fib = fibonacci()
for i in range(10):
print(next(fib))上面的代码定义了一个名为 fibonacci() 的生成器函数,使用 yield 语句生成斐波那契数列。在主程序中,创建了一个生成器对象 fib,并通过 next() 方法调用了10次,每次调用都会输出一个斐波那契数列的元素。
生成器是一种非常强大的工具,可以用来处理大量的数据,提高程序的效率,也可以用来实现协程,完成异步编程等高级应用。
在生成器函数中,通常会使用 while True 循环来不断生成数据。这是因为生成器是一种惰性求值的迭代器,它只在需要时才会生成数据,并且可以不限次数地生成数据。因此,当我们在使用生成器时,通常会通过 next() 方法不断从生成器中取出数据,直到生成器结束。
在生成器函数中使用 while True 循环,可以保证生成器可以不限次数地生成数据,直到程序主动终止或者生成器函数内部返回一个 StopIteration 异常来结束生成器。在 while True 循环中,通常还会使用 yield 语句来返回生成器的值,因此每次调用 next() 方法时,都会从上次暂停的位置继续执行生成器函数,并生成下一个值,直到结束为止。
惰性求值(Lazy evaluation)是一种编程语言的求值策略,它的特点是在程序需要使用数据时才进行求值。与之相对的是及早求值(Eager evaluation),它的特点是在程序执行时尽可能早地对表达式进行求值。
在惰性求值的策略中,表达式的求值被推迟到程序需要使用它的结果时。这种策略的优势在于可以避免一些不必要的计算和存储,从而提高程序的效率和性能。另外,惰性求值还可以让程序具有更好的组合性和灵活性,因为程序可以按需组合各种操作,并且不必事先计算所有的结果。
在 Python 中,生成器是一种惰性求值的迭代器,它只在需要时才会生成数据,并且可以不限次数地生成数据。通过使用生成器,我们可以避免一次性生成大量的数据导致内存溢出等问题,同时也可以使程序具有更好的组合性和灵活性。除了生成器,Python 中还有一些惰性求值的工具和函数,例如 map()、filter() 和 zip() 等。
map()、filter() 和 zip()
这三个函数是 Python 内置的用于操作可迭代对象的函数,它们都属于惰性求值的策略。
map()
numbers = [1, 2, 3, 4, 5]
squares = map(lambda x: x**2, numbers)
print(list(squares)) # [1, 4, 9, 16, 25]map() 函数接受一个函数和一个可迭代对象,它会对可迭代对象中的每个元素应用函数,并返回一个新的可迭代对象。例如,我们可以使用 map() 函数对列表中的所有元素求平方:
filter()
filter() 函数接受一个函数和一个可迭代对象,它会对可迭代对象中的每个元素应用函数,返回所有使函数返回 True 的元素组成的新的可迭代对象。例如,我们可以使用 filter() 函数过滤掉列表中的奇数:
numbers = [1, 2, 3, 4, 5]
even_numbers = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers)) # [2, 4]
zip()
zip() 函数接受多个可迭代对象,它会返回一个新的可迭代对象,其中每个元素是输入的可迭代对象中对应位置的元素组成的元组。例如,我们可以使用 zip() 函数将两个列表按位置组合:
names = ["Alice", "Bob", "Charlie"]
ages = [20, 30, 40]
data = zip(names, ages)
print(list(data)) # [("Alice", 20), ("Bob", 30), ("Charlie", 40)]这三个函数都是非常常用的 Python 内置函数,它们可以让我们在不显式遍历可迭代对象的情况下,对其进行操作和处理,从而提高程序的效率和可读性。同时,它们也支持惰性求值的特性,可以处理非常大的数据集而不会造成内存溢出等问题。
1、*args保存多余变量,保存方式为元组。
2、**args保存带有变量名的多余变量,保存方式为字典。

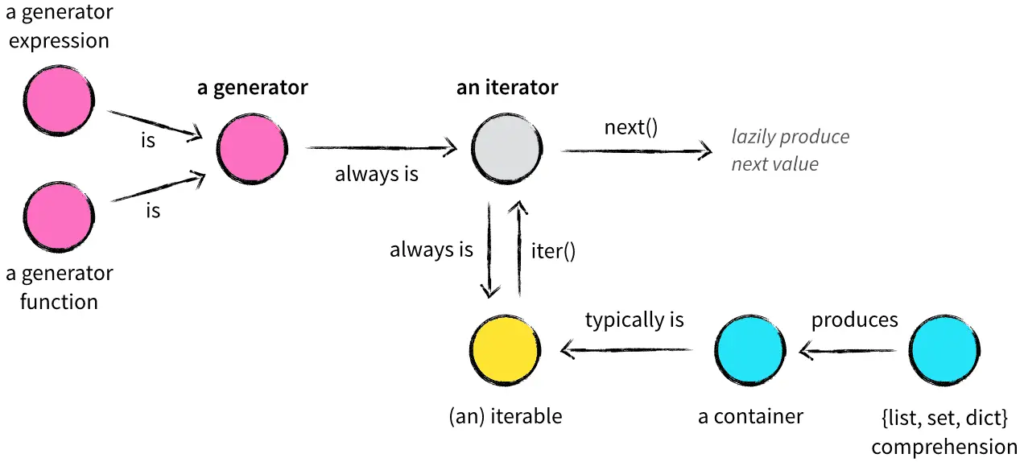
迭代器在访问元素时不会复制可迭代对象,它只是在内部维护一个指针(或索引),用以记录当前访问的位置。
在 Python 中,要构造一个可迭代对象,需要实现 __iter__() 方法。可迭代对象可以是任何实现了 __iter__() 方法并返回一个迭代器的对象。
迭代器对象还需要实现 __next__() 方法,以便可以逐一访问元素。
class MyRange:
def __init__(self, start, end):
self.start = start
self.end = end
def __iter__(self):
return MyRangeIterator(self.start, self.end)
class MyRangeIterator:
def __init__(self, start, end):
self.current = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.current >= self.end:
raise StopIteration
else:
current = self.current
self.current += 1
return current
# 使用自定义的可迭代对象
my_range = MyRange(1, 5)
for num in my_range:
print(num) # 输出: 1 2 3 4
生成器是一种特殊的迭代器ーー优雅的迭代器。
推导式 Comprehension
Comprehension是一种简洁的语法结构,用于生成新的序列(如列表、集合、字典等)。Python支持四种主要的comprehension:列表推导式(List Comprehension)、集合推导式(Set Comprehension)、字典推导式(Dictionary Comprehension)和生成器表达式(Generator Expression)。
[表达式 for 变量 in 可迭代对象 if 条件]字符串方法
Fredrik Lundh 曾经建议以下一组规则来重构 lambda 的使用:
- 写一个 lambda 函数。
- 写一句注释来说明这个 lambda 究竟干了什么。
- 研究一会这个注释,然后想出一个抓住注释本质的名字。
- 用这个名字,把这个 lambda 改写成 def 语句。
- 把注释去掉。
“超类”是指一个类的父类或基类。一个类可以从一个或多个超类继承属性和方法。继承是面向对象编程中的一个重要概念,它允许你创建一个新类,该类可以重用一个或多个已存在类的属性和方法。
子类化是指创建一个新的类,该类从一个或多个已存在的类中继承属性和方法。新创建的类称为子类,而被继承的类称为父类或超类。子类可以继承父类的特性,并且可以通过添加新的属性和方法来扩展或修改其行为。
Python 切片语法是一种便捷的方法,用于从序列(如列表、元组、字符串等)中提取部分元素。Python 的切片操作非常灵活,基本语法如下:
arduino
Copy code
序列[start:stop:step]
这里,start、stop 和 step 分别表示切片的起始位置、终止位置和步长。下面是具体的介绍:
- start: 切片的开始索引,序列从这里开始提取。如果不指定,默认从序列的开始处提取。
- stop: 切片的结束索引,序列在这里结束提取,但不包括此索引指向的元素。如果不指定,默认提取到序列的末尾。
- step: 步长决定了从
start到stop间提取元素的间隔。如果不指定,默认步长为1,即连续提取。步长可以是负数,这时会逆向提取元素。
示例
- 基本切片:pythonCopy code
lst = [0, 1, 2, 3, 4, 5] print(lst[1:4]) # 输出: [1, 2, 3] - 省略开始或结束索引:pythonCopy code
print(lst[:3]) # 输出: [0, 1, 2] print(lst[3:]) # 输出: [3, 4, 5] - 负数索引:pythonCopy code
print(lst[-4:-1]) # 输出: [2, 3, 4] - 步长使用:pythonCopy code
print(lst[0:5:2]) # 输出: [0, 2, 4] print(lst[::-1]) # 输出: [5, 4, 3, 2, 1, 0], 逆序列表
注意点
- 如果
start或stop指定的索引超出了序列的范围,Python 会自动将其调整到序列的边界。 - 切片操作返回一个新的序列,不影响原始序列。
切片是处理数据时非常有用的工具,能够简洁地表达复杂的序列操作。在数据处理、机器学习等领域中非常常见。
在类内部定义的函数。如果作为该类的实例的一个属性来调用,方法将会获取实例对象作为其第一个 argument (通常命名为 self)。参见 function 和 nested scope。
任何定义了 __get__(), __set__() 或 __delete__() 方法的对象。 当一个类属性为描述器时,它的特殊绑定行为就会在属性查找时被触发。 通常情况下,使用 a.b 来获取、设置或删除一个属性时会在 a 类的字典中查找名称为 b 的对象,但如果 b 是一个描述器,则会调用对应的描述器方法。 理解描述器的概念是更深层次理解 Python 的关键,因为这是许多重要特性的基础,包括函数、方法、特征属性、类方法、静态方法以及对超类的引用等等。
在 Python 中,is not 和 != 是两个不同的运算符,它们用于不同的比较场景。以下是它们的区别:
1. !=(不等于运算符)
- 功能:
!=用于比较两个对象的值是否不相等。 - 适用场景:当你想要比较两个对象的内容或值是否不同时,使用
!=。 - 示例:
a = [1, 2, 3] b = [1, 2, 3] print(a != b) # False,因为 a 和 b 的值相等
2. is not(身份运算符)
- 功能:
is not用于比较两个对象的身份(即内存地址)是否不同。 - 适用场景:当你想要判断两个对象是否不是同一个对象(即它们是否指向不同的内存地址)时,使用
is not。 - 示例:
a = [1, 2, 3] b = [1, 2, 3] print(a is not b) # True,因为 a 和 b 是不同的对象,即使它们的值相同
关键区别
!=比较的是值是否相等。is not比较的是身份(内存地址)是否相同。
示例对比
x = [1, 2, 3] y = [1, 2, 3] z = x print(x != y) # False,因为 x 和 y 的值相等 print(x is not y) # True,因为 x 和 y 是不同的对象 print(x != z) # False,因为 x 和 z 的值相等 print(x is not z) # False,因为 x 和 z 是同一个对象
总结
- 使用
!=来比较两个对象的值是否不同。 - 使用
is not来比较两个对象是否是同一个对象(即它们是否指向相同的内存地址)。