损失函数 Loss Function
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
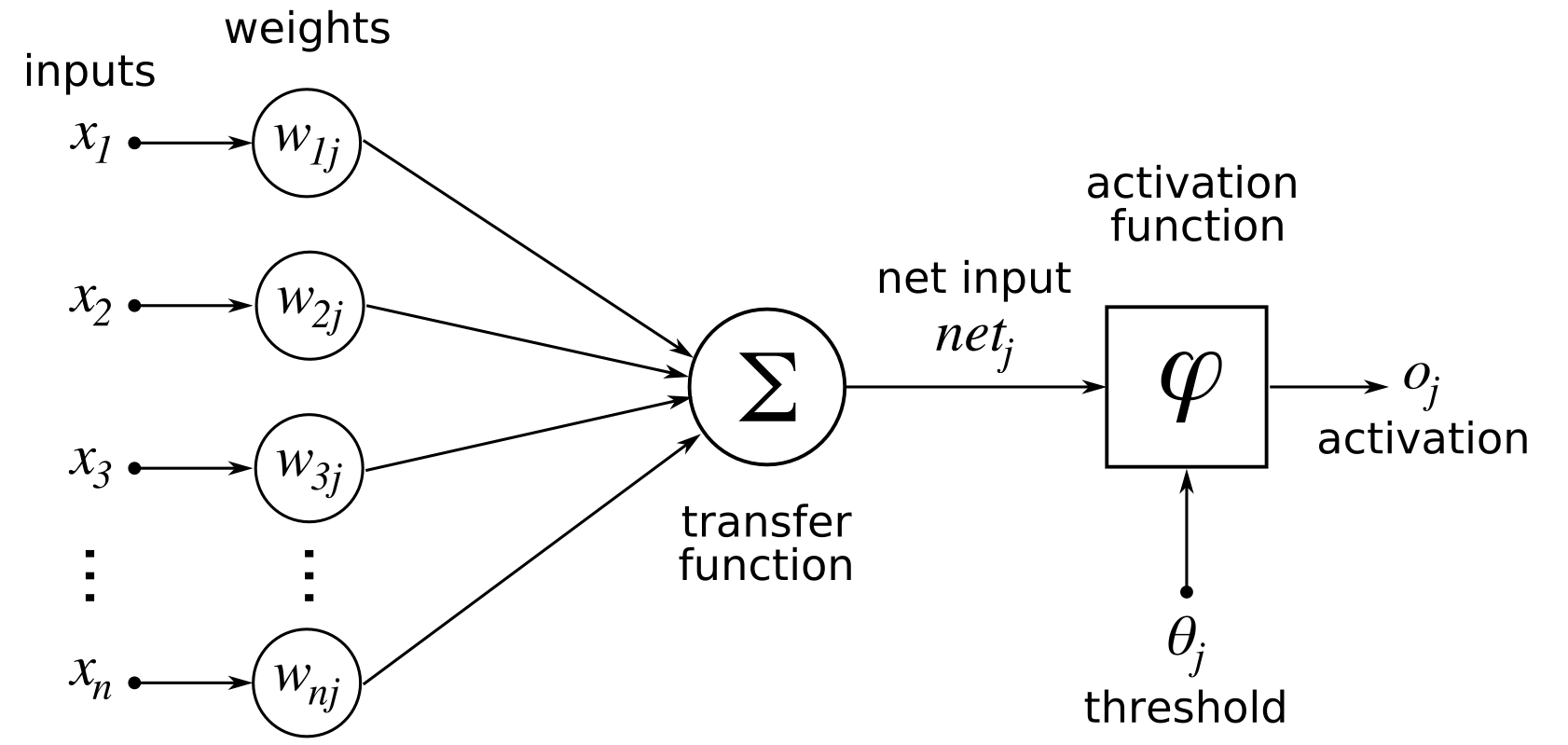
前馈神经网络 Feedforward neural network
梯度下降 Gradient Descent
梯度爆炸 gradient exploding problem
梯度消失 gradient vanishing problem
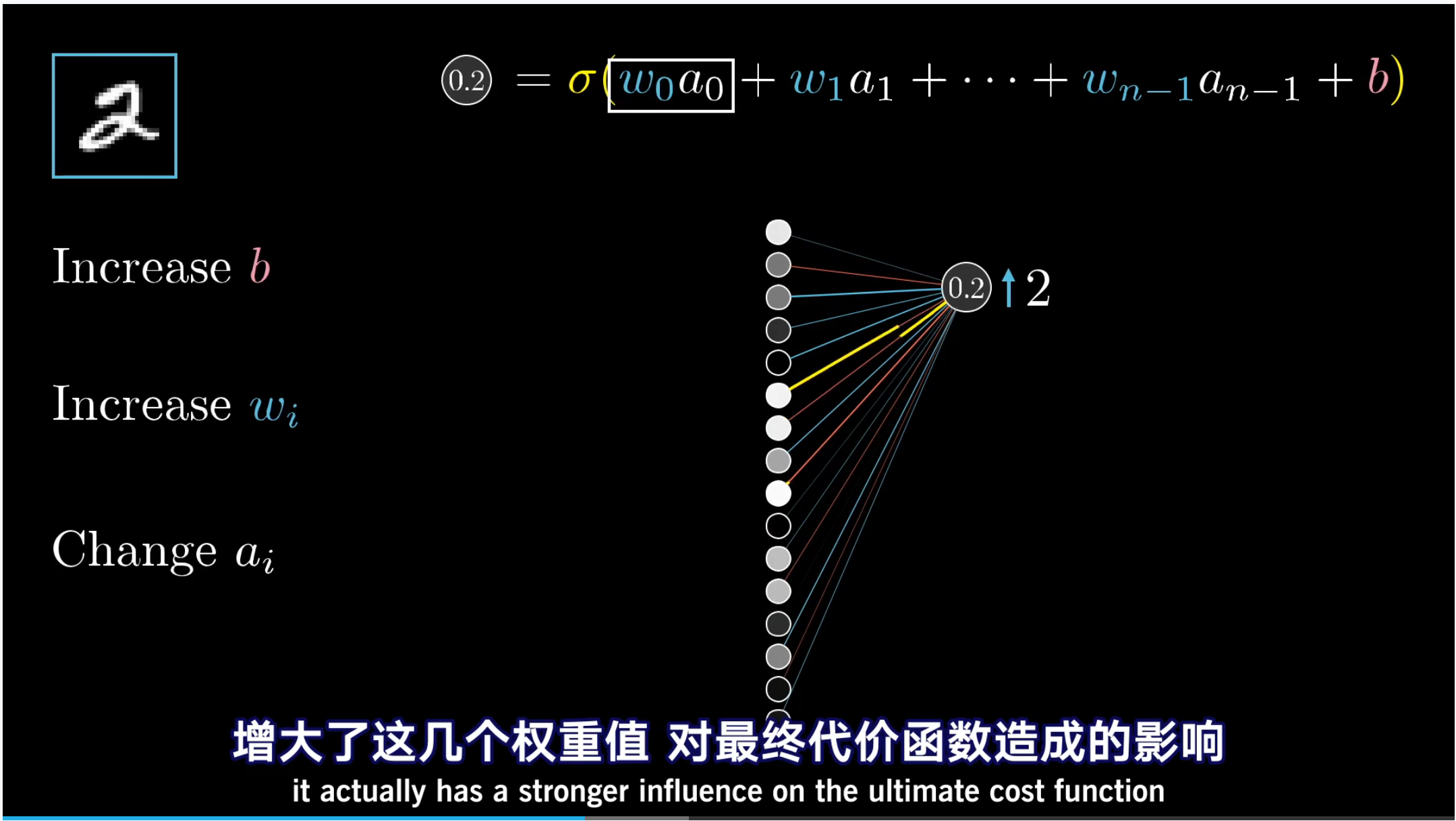
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
梯度 gradient
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
机器学习 Machine Learning ML 是指从有限的观测数据中学习(或”猜测“)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。
风险函数 是损失函数的期望值
SOTA model:state-of-the-art model,并不是特指某个具体的模型,而是指在该项研究任务中,目前最好/最先进的模型。
SOTA result:state-of-the-art result,指的是在该项研究任务中,目前最好的模型的结果/性能/表现。
Adam算法