容器 (Container)
定义 :存储元素并支持成员测试 (in / not in) 的数据结构,通常将所有元素保存在内存中。
特点 :对象必须是实体化的数据结构。
常见类型 :
# 列表 ( List ) assert 1 in [ 1 , 2 , 3 ] # 集合 ( Set ) assert 1 in { 1 , 2 , 3 } # 元组 ( Tuple ) assert 1 in ( 1 , 2 , 3 ) # 字典 ( Dict ) 测试键 d = { 1 : ' a ' , 2 : ' b ' } assert 1 in d # True assert ' a ' not in d # True # 字符串 ( String ) 测试子串 s = ' hello ' assert ' he ' in s # True
关键点 :
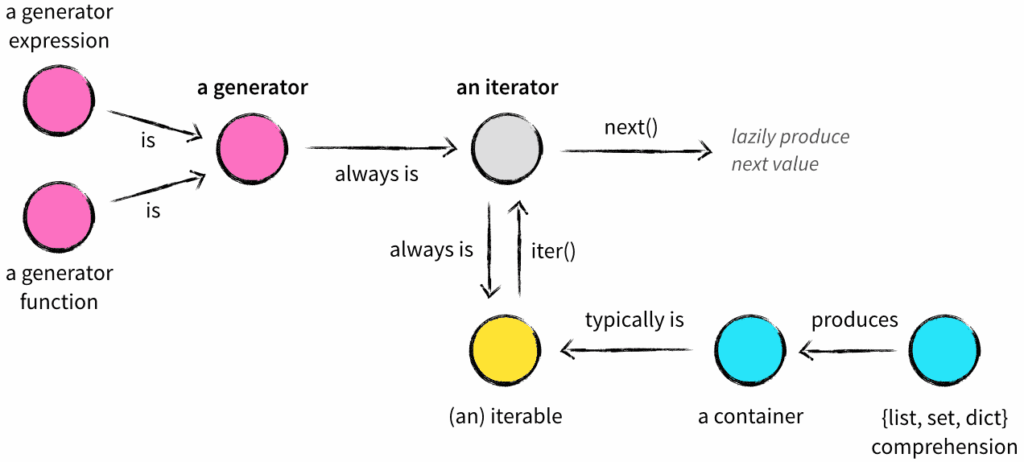
容器 ≠ 迭代能力(如 Bloom Filter 是容器但不可迭代)。
成员测试针对数据结构特性(字典测键、字符串测子串)。
可迭代对象 (Iterable)
定义 :能返回迭代器的任意对象(不限于数据结构)。可通过 iter() 获取其迭代器。
特点 :可表示有限或无限数据流(如文件、网络流)。
示例 :
x = [ 1 , 2 , 3 ] # 列表是可迭代对象 y = iter ( x ) # 获取迭代器 print ( next ( y )) # 1 ( 迭代器保存状态 ) # for 循环的等效操作 x = [ 1 , 2 , 3 ] iterator = iter ( x ) # 获取迭代器 while True : try : elem = next ( iterator ) # 依次获取元素 except StopIteration : break 迭代器 (Iterator)
定义 :带有状态的对象,通过 __next__() 方法逐个返回值。
特点 :
惰性求值:调用 next() 时才计算/返回数据。
消耗性:遍历后不可重置(需重新创建迭代器)。
示例 :
from itertools import count , cycle , islice # 无限迭代器 counter = count ( start =10) print ( next ( counter )) # 10 # 有限迭代器 ( 从无限序列截取 ) colors = cycle ([ ' red ' , ' blue ' ]) limited = islice ( colors , 0 , 3) # [ ' red ' , ' blue ' , ' red ' ] 生成器 (Generator)
定义 :通过 yield 创建的迭代器,无需手动实现 __next__()。
特点 :语法简洁,自动保存执行状态。
生成器函数示例 (斐波那契数列)
def fib (): prev , curr = 0 , 1 while True : yield curr prev , curr = curr , prev + curr f = fib () print ( list ( islice ( f , 0 , 5 ))) # [ 1 , 1 , 2 , 3 , 5 ] f = fib() 不执行代码,调用 next(f) 时运行到 yield 暂停。
生成器表达式 (Generator Expression)
定义 :类似列表推导的惰性版本,语法为 (expr for item in iterable)。
特点 :节省内存,一次产生一个值。
示例 :
numbers = [ 1 , 2 , 3 ] lazy_squares = ( x * x for x in numbers ) # 生成器对象 print ( next ( lazy_squares )) # 1 print ( list ( lazy_squares )) # [ 4 , 9 ]( 状态已推进 ) 推导式 (Comprehension)
定义 :快速构建容器(列表/集合/字典)的语法。
特点 :立即求值,直接生成内存数据结构。
常见类型 :
# 列表推导式 [ x * x for x in [ 1 , 2 , 3 ]] # → [ 1 , 4 , 9 ] # 集合推导式 { x * x for x in [ 1 , 2 , 3 ] } # → { 1 , 4 , 9 } ( 无序 ) # 字典推导式 { x : x * x for x in [ 1 , 2 , 3 ] } # → { 1 : 1 , 2 : 4 , 3 : 9 }
与生成器表达式对比 :推导式 生成器表达式 返回完整容器(如列表)返回惰性迭代器立即执行,占用内存惰性求值,节省内存
核心区别 :
容器 :存储元素,支持 in 测试。
可迭代对象 :能返回迭代器(iter())。
迭代器 :通过 __next__() 逐个返回值(带状态)。
生成器 :用 yield 简化的迭代器。
生成器表达式 :惰性推导式(返回迭代器)。
推导式 :立即生成容器(列表/集/字典)。
实践建议 :将逐步构建列表的函数转为生成器,即:
def generate_data (): # 生成器节省内存 for ... in ... : yield result # 必要时再转换为列表 data = list ( generate_data ())
for 语句for
for_stmt ::= "for" target_liststarred_list ":" suitesuitestarred_list 表达式会被求值一次;它应当产生一个 iterable 对象。 将针对该可迭代对象创建一个 iterator 。 随后该迭代器所提供的第一个条目将使用标准的赋值规则被赋值给目标列表 (参见 赋值语句 ),而代码块将被执行。 此过程将针对该迭代器所提供每个条目重复进行。 当迭代器被耗尽时,如果存在 else 子句中的代码块,则它将被执行,并终结循环。
第一个子句体中的 breakelse 子句体。 第一个子句体中的 continueelse 子句执行。
for 循环会对目标列表中的变量进行赋值。 这将覆盖之前对这些变量的所有赋值,包括在 for 循环体中的赋值:
for i in range(10):
print(i)
i = 5 # 这不会影响 for 循环
# 因为它将被 range 对象中的下一个索引
# 所覆盖
目标列表中的名称在循环结束时不会被删除,但是如果序列为空,则它们将根本不会被循环所赋值。 提示:内置类型 range()range(3) 将依次产生 0, 1 和 2。
在 3.11 版本发生变更: 现在允许在表达式列表中使用带星号的元素。